
 33923570(021)-09940579376
33923570(021)-09940579376




کـارت گرافیـک محـاسبـاتی(نـو)انویدیا تسـلا(ولتــا) NVIDIA Tesla V100 32GB CoWoS HBM2 PCIe Volta Tensor Core GPU Accelerator(New)
اولیـن شتــاب دهنـده گـرافیــکی Tensor Core در دنیـــا
قدرتمندترین پردازنده گرافیکی جهان، NVIDIA® V100 Tensor Core GPU قدرتمندترین شتاب دهنده مرکزداده جهان است که تاکنون؛ به منظور علم داده (Data Science)، هوش مصنوعی (AI)، یادگیری عمیق (DL)، یادگیری ماشین (ML)، محاسبات با کارایی بالا (HPC) و گرافیک ساخته شده است. به عنوان اولین پردازنده گرافیکی تنسور کُر در دنیا(The First Tensor Core GPU)، و با پشتیبانی از NVIDIA Volta™، یک واحد پردازشگر گرافیکی V100 Tensor Core ، عملکرد تقریباً 32 عدد CPU را ارائه داده، و محققان را قادر میسازد تا با چالشهایی که زمانی غیرقابل حل بودند مقابله کنند. V100 برنده MLPerf، اولین معیار هوش مصنوعی در صنعت شده، و جایگاه خود را به عنوان قدرتمندترین، مقیاس پذیرترین و همه کاره ترین پلت فرم محاسباتی جهان تثبیت نموده است.
محصولات مرتبط










به عصر هوش مصنوعی خوش آمدید!
یافتن بینشهای پنهان در اقیانوسی از داده ها، قادر به متحول ساختن کل صنایع می باشد؛ از درمان شخصیشده سرطان گرفته، تا کمک به دستیاران شخصی مجازی، که به طور طبیعی با هم گفتگو کنند، و طوفان بزرگ بعدی را پیشبینی کنند.
NVIDIA® Tesla® V100 Tensor Core پیشرفتهترین پردازنده گرافیکی مرکز داده است که تا کنون برای تسریع هوش مصنوعی (AI)، محاسبات با کارایی بالا (HPC)، علم داده(Data Science) و گرافیک ساخته شده است.
این پردازنده از معماری NVIDIA Volta پشتیبانی میکند، در پیکربندیهای 16 و 32 گیگابایتی ارائه میشود و عملکرد 100 تا CPU را در یک GPU ارائه میکند.
دانشمندان داده(Data Scientist)، محققان و مهندسان(Engineers) اکنون این فرصت بی سابقه را یافته؛ تا زمان کمتری را صرف بهینه سازی استفاده از حافظه کنند، و زمان بیشتری را برای طراحی پیشرفت هوش مصنوعی بعدی صرف کنند.
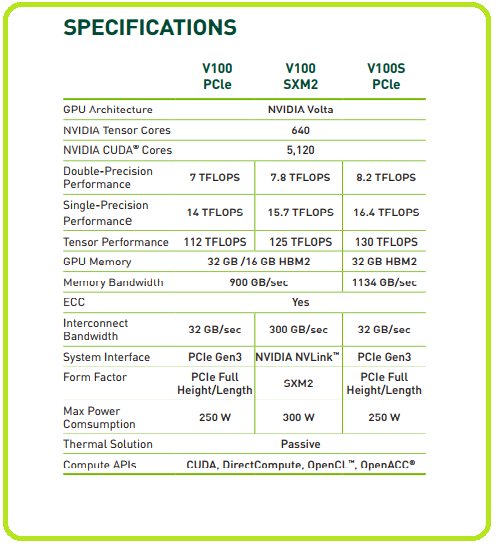
نسخه GPU 16 گیگابایتی NVIDIA Tesla V100 که برای پاسخگویی به؛ نیازهای بسیاری از سیستمهای محاسباتی مدرن طراحی شده است، برای پیادهسازی با استفاده از اسلاتهای PCIe، رایجترین فرم فاکتور مورد استفاده، می باشد.
نسخه PCIe همچنین در مقایسه با، نسخه SXM2 که از NVLink برای ارتباط مستقیم با CPU استفاده می کند، در نقطه قدرت طراحی حرارتی پایین تری کار می کند.
هر دو پردازنده گرافیکی NVIDIA Tesla V100 16GB و NVIDIA Tesla V100 32GB برای یادگیری عمیق DL(Deep Learning)، شیمی کوانتومی (Quantum Chemistry)، امور مالی (Finance)، آب و هوا (Weather)و موارد دیگر ایده آل هستند.

V100 محصول شاخص پلتفرم مرکز داده NVIDIA برای یادگیری عمیق(NVIDIA data center platform for deep learning)، HPC و گرافیک است. این پلتفرم به بیش از 600 برنامه HPC و هر چارچوب یادگیری عمیق اصلی سرعت می بخشد. این در همه جا در دسترس بوده، و از رایانه های رومیزی گرفته تا سرورها و خدمات ابری(Cloud Services)، که هم دستاوردهای چشمگیر عملکرد و هم فرصت های صرفه جویی در هزینه را ارائه می دهند.


1- معماری VOLTA
با جفت کردن هستههای CUDA و هستههای Tensor ،در یک معماری واحد، یک سرور واحد با پردازندههای گرافیکی V100 ،قابلیت جایگزینی با صدها سرور و CPU هاشان، برای HPC سنتی و یادگیری عمیق شود.
2- هسته تانسور (Tensor Cores)
V100 مجهز به 640 هسته تانسور، 130teraFLOPS (130 TFLOPS) عملکرد یادگیری عمیق (DL Performance) را ارائه می دهد. این درحالست که 12X Tensor FLOPS برای آموزش یادگیری عمیق (DL Training) و 6X Tensor FLOPS برای استنتاج یادگیری عمیق (DL Inference) در مقایسه با GPU های NVIDIA Pascal™ می باشد.
دیدگاه خود را بنویسید